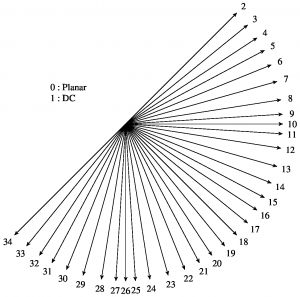
 A set of 35 intra prediction modes is available in HEVC, including a DC, a planar, and 33 angular prediction modes.While the DC and the planar mode are targetting at flat areas or areas with few structure, the angular modes provide directional prediction in a very granular way.
A set of 35 intra prediction modes is available in HEVC, including a DC, a planar, and 33 angular prediction modes.While the DC and the planar mode are targetting at flat areas or areas with few structure, the angular modes provide directional prediction in a very granular way.
The modes are available for prediction block sizes from 4×4 to 32×32 samples. For luma and chroma blocks, the same prediction modes are applied. Some of the smoothing operations applied for luma intra prediction are omitted for chroma blocks as further
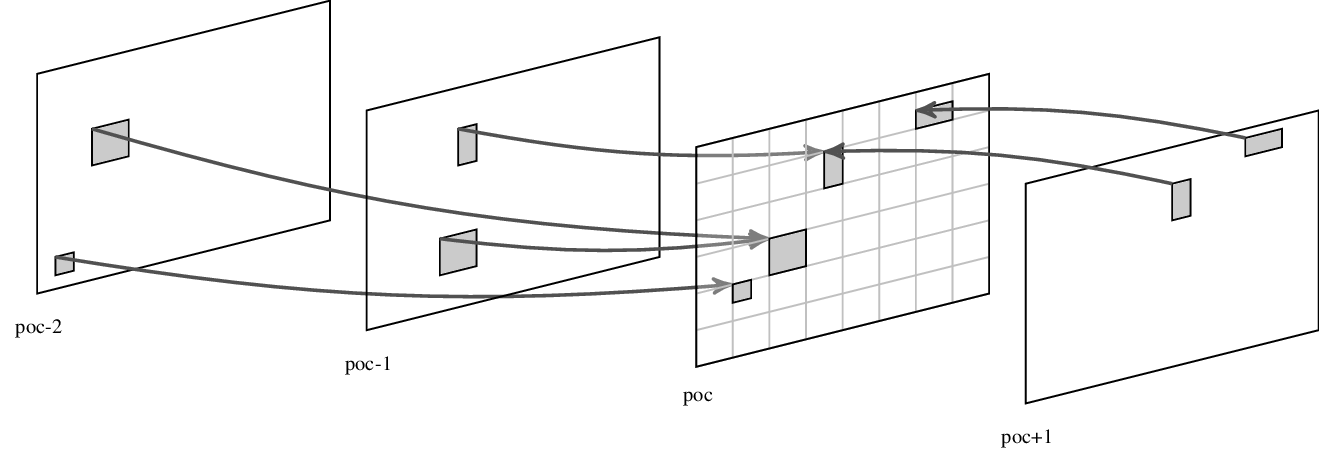
detailedbelow.The prediction reference is constructed from the sample row and column adjacent to the predicted block. The reference extends over two times the block size in horizontal and vertical direction using the available sample from previously reconstructed blocks.